Speech Illustrator
Speech Illustrator 是一款将语音实时转化为对应图像的AI工具,适用于有声书、播客等多种场景,支持90多种语言,并可自定义艺术风格。
Speech Illustrator 介绍
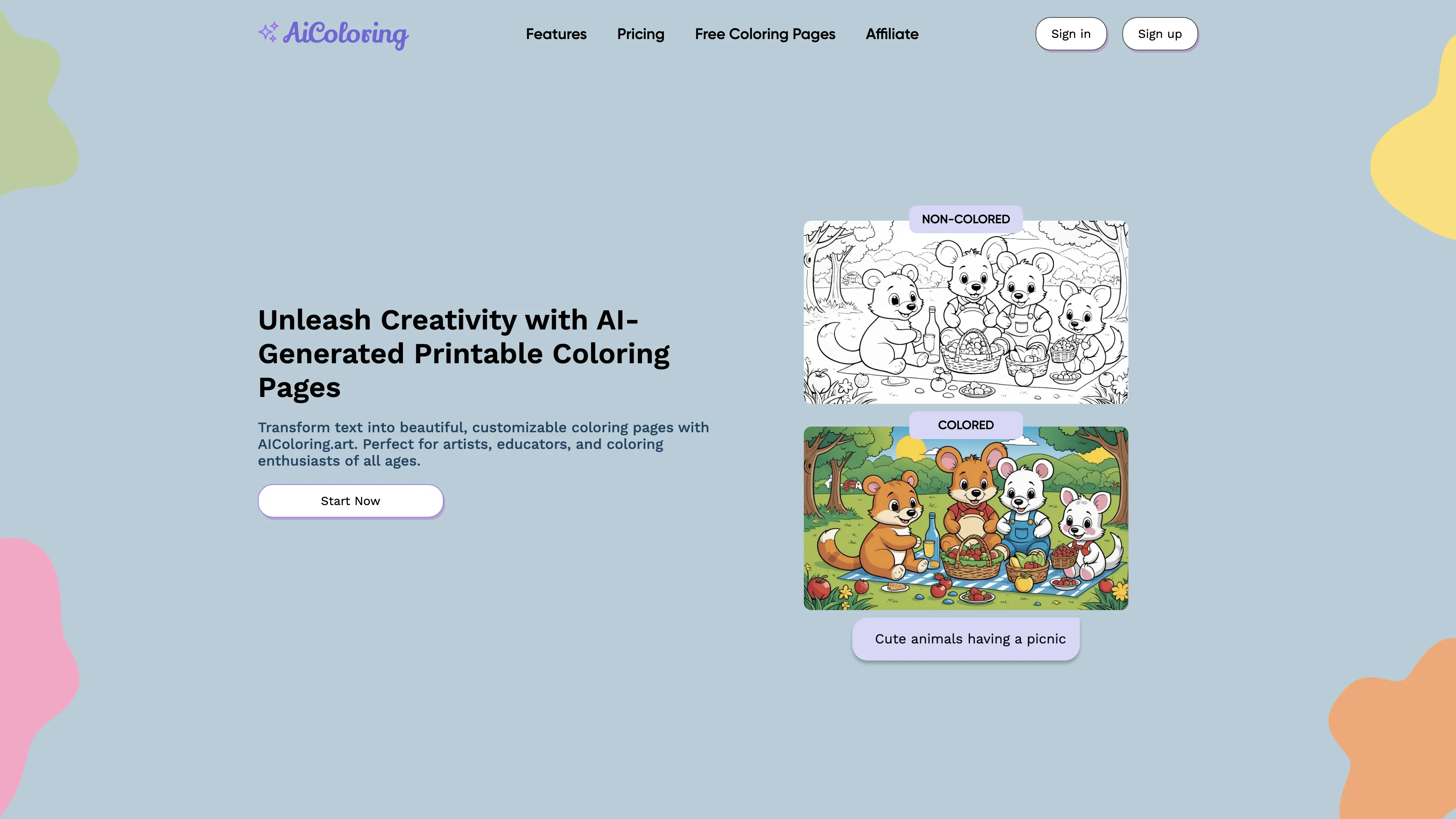
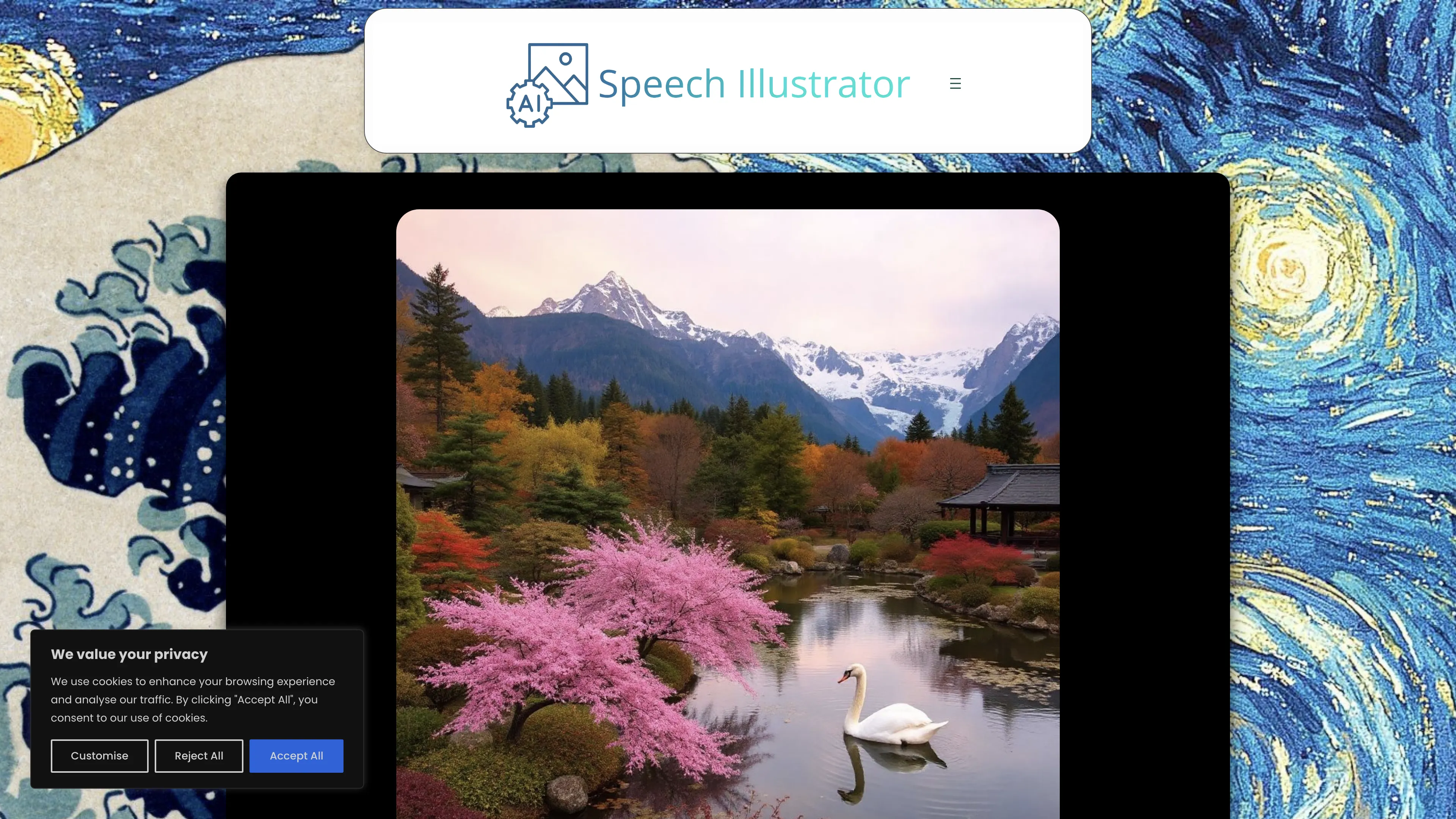
Speech Illustrator 是一个能实时将语言转化为对应图像的人工智能工具。其最大亮点在于广泛的应用范围,从有声书、播客、歌曲到讲座甚至日常对话。这一功能让任何形式的语音内容都有了全新的视觉体验。它兼容多种设备和媒体平台,如Audible、Spotify和Apple Podcasts,并且能理解超过90种语言,尤其是对英语的解释效果最佳。用户可以根据自己喜好设置生成图像的频率和绘画风格,也能选择通过麦克风或系统音频获取音源(系统音频仅限Windows和Chrome OS)。生成的图像还可以下载保存。值得注意的是,互联网连接质量可能会影响工具的性能。整体来说,Speech Illustrator 无疑为各类语音内容增添了视觉上的趣味和美感,不再仅仅是听觉盛宴。
Speech Illustrator 主要功能
实时语言转图片
Speech Illustrator 利用AI技术将口语实时转换为相应的图片,为有声书、播客、歌曲等提供独特的视觉体验。
多平台兼容性
兼容多种设备和平台,包括Audible、Spotify和Apple Podcasts,使用户能够轻松在不同媒体上使用。
多语言支持
支持90多种语言的理解,尽管以英语表现最优,确保全球用户都能享受这个工具的便利。
自定义艺术风格
用户可以根据个人喜好设置特定的艺术风格,或让AI自动根据内容调整,增强个性化体验。
高效图像下载
生成的图片可直接下载,方便用户收藏和分享。
Speech Illustrator 使用案例
教育辅助:学生通过Speech Illustrator在听讲座时,AI实时生成的图像帮助他们更好地理解复杂的概念。通过视觉增强学习,学生们能够更有效地记住信息,提高学习效率。
播客视觉化:播客制作人使用Speech Illustrator实时将音频内容转化为生动的图像,吸引听众的目光,不仅增加了节目的娱乐性,还扩大了受众范围。
歌曲解读:音乐家在创作或分享歌曲时,通过Speech Illustrator生成的艺术图像,呈现出歌曲背后的情感和故事,帮助听众更深入地感受音乐。
多语言交流:多语言会议上,Speech Illustrator可以生成对应的图像辅助交流,不论是哪种语言的演讲者,大家都能通过图像共通理解主题,提升会议效果。
创意写作:作家使用Speech Illustrator在讲述故事时,实时生成的图像创意激发他们新的灵感,使故事更加生动和具象,同时还能跟读者分享这些视觉作品。
Speech Illustrator 用户指南
Step 1: 选择更新间隔,你希望多长时间生成一幅新图。
Step 2: 可选设置自定义的艺术风格,留空默认根据内容变化。
Step 3: 选择音频来源,是麦克风还是系统音频(仅限Windows和Chrome OS)。
Step 4: 准备好要播放的音频内容,如有声书、播客或演讲。
Step 5: 点击播放,等待大约30秒后享受生成的图像。
Speech Illustrator 常见问题
Speech Illustrator 网站分析
Speech Illustrator 替代品
Supawork AI提供免费AI生成的专业头像、个性化求职信和多语言简历翻译,提升求职成功率,支持无注册快速操作。
AI Image to Image Generator通过先进的AI技术,将照片转换为艺术风格,提供高质量结果和丰富的创意选项,适合个人和商业用途。